
La configuration d’un cluster Nutanix est relativement simple et rapide, même lorsque l’hyperviseur est du VMware vSphere. Cependant, je rencontre souvent un problème lorsqu’il s’agit de vérifier la synchronisation NTP de toutes les CVM du cluster Nutanix. L’article présent liste tous les steps pour faire le debug de la configuration NTP. Premièrement, on part du principe que tous les flux firewall sont ouvert entre votre réseau de vmkernel ESXi (Management) / CVM et la target NTP (privée ou public).
Lors de la création du cluster, la timezone qui est configurée est en PST (heure américaine), il est important de changer celle-ci en Europe/Paris (définit dans cet article précédent). Ajoutez ensuite vos NTP serveurs dans la console Prism. Assurez-vous également de correctement mettre à l’heure vos IPMI/iDRAC et ESXi manuellement puis de spécifier les adresses des serveurs NTP.
Théoriquement, votre cluster est prêt à entrer en production MAIS lorsque vous regarder l’heure de vos CVM, vous avez peut_être 1h ou 2h dans le futur par rapport à votre montre. Comment vérifier cette information ? Connectez-vous en ssh sur une des CVM et tapez la commande suivante : “allssh date“. Pourquoi le NTP est-il tant problématique sur les CVM ? la base Cassandra, qui gère l’ensemble des metadatas de votre cluster Nutanix, utilise des timestamps pour chaque entrée. Ainsi, le changement d’heure peut être problématique. Si jamais vous êtes dans le futur de plus de 5 secondes, les CVM ne pourront en aucun cas se synchroniser avec vos serveurs NTP.
PS : Si jamais l’heure des CVM est dans le passé, ne paniquez pas car le changement se fera automatiquement avec l’ajout des NTP dans Prism 🙂
Deux choix s’offre à vous pour régler le problème du temps dans le futur :
- Corriger l’heure sans interruption de service via un script de timedrift fourni par Nutanix
- Corriger l’heure avec arrêt du cluster Nutanix et attendre le temps
Vérifier la synchronisation avec les serveurs NTP
Comment vérifier la synchronisation avec les serveurs NTP ? Tapez la commande : “allssh ntpq -p” (CVM) ou “hostssh ntpq -p” (ESXi). L’option “-p” permet de lister les peer NTP, la capture suivante utilise simplement l’option “-n” qui permet de renseigner les IP plutôt que les noms.

Pas de synchronisation NTP effective
On peut bien voir la différence entre les deux commandes. Les ESXi se synchronisent bien avec les NTP alors qu’il n’y a aucune référence NTP dans la commande des CVM. Toutes les CVM du cluster se synchronisent avec une CVM qui est NTP master afin d’avoir une cohérence au niveau du cluster. Mais celle-ci se base sur son horloge locale ! Ce qui n’est pas la configuration recommandée. Si votre temps est dans le futur, vous aurez ce phénomène.
Pour aller plus loin, vous pouvez même aller chercher dans les logs pour comprendre l’origine du problème : grep -i ntp data/logs/genesis.out. Dans le cas suivant, on peut voir que Nutanix refuse de se synchroniser avec ce serveur NTP parce que le temps de réponse n’est pas correcte.

Error log – Configuration NTP (genesis.out)
Pour les best pratices Nutanix (lien) :
- Privilégiez au minimum 3 serveurs NTP différents afin que Nutanix identifie une source qui peut potentiellement ne pas être correcte (sans redondance). 4 serveurs permet d’avoir une redondance, 5 est le nombre recommandé.
- Privilégiez des NTP internes pour la stabilité du réseau et la sécurité. Sinon utilisez les pools publiques avec le stratum le plus faible.
- Les NTP Windows sont à éviter.
- Privilégiez les noms de domaines afin de pallier à un éventuel changement d’IP (pour les pools publiques).
Vous pouvez vérifier que vos CVM communiquent bien et sont suceptibles de se synchroniser avec les NTP grâce à la commande ci-dessous. L’option “-q” permet simplement de faire une query, ainsi vous savez si celle-ci vous retourne quelque chose de cohérent : ntpdate –q xxx.xxx.xxx.xxx. Si le stratum est à 0, le serveur NTP n’est pas joignable et la query ne fonctionne pas. Si ce dernier est entre 1 et 15 (privilégiez en dessous de 5), la synchronisation est possible. Si la valeur est de 16, le serveur NTP est joignable mais il est lui-même désynchronisé.

Query NTP
Corriger l’heure sans interruption de service
Si jamais vous avez déjà de la production critique sur votre cluster Nutanix qui tourne, suivez cette procédure pour revenir dans le passé. Je préviens d’avance, ca va être long. En effet, cette méthode permet de revenir dans le passé en grapillant quelques dizaines de secondes par jour.
Chaque CVM stocke un script prévu par Nutanix qui permet de revenir dans le passé sans impacter la base Cassandra. Pour l’activer, nous allons ajouter l’exécution du script dans le crontab de chaque CVM du cluster via la commande suivante : allssh ‘(/usr/bin/crontab -l && echo “*/5 * * * * bash -lc /home/nutanix/serviceability/bin/fix_time_drift”) | /usr/bin/crontab -‘

Activation du script Timedrift
Vous pouvez vérifier l’offset de chaque CVM via la commande suivante : allssh grep offset ~/data/logs/genesis.out
Une fois que cet offset (négatif) arrive à 0 seconde ou devient positif (si jamais vous le laissez tourner plus longtemps que prévu), nous allons enlever l’exécution du script dans le crontab des CVM via la commande suivante :
allssh “(/usr/bin/crontab -l | sed ‘/fix_time_drift/d’ | /usr/bin/crontab -)”
Astuce : Activez cette fonctionnalité et vérifiez l’offset au bout de 12h ou 24h, faites un produit en croix pour estimer le temps restant. On peut facilement parler de plusieurs semaines ou mois lorsque le drift est important. Appuyez-vous sur votre agenda pour vous mettre des reminders 🙂
Corriger l’heure avec interruption de service
Voici la méthode la plus rapide mais qui n’est pas à la portée de tous : l’arrêt du cluster et manuellement changer l’heure du cluster. Cependant il ne s’agit pas d’un simple arrêt, nous allons également attendre toute la durée de l’offset avec le cluster arrêté. En effet, si vous tentez de redémarrer votre cluster 10 minutes après alors que vous être revenu 1h dans le passé, la commande va échouer. Vous pouvez alors voir un message qui explique que des entrées dans la base Cassandra ont été détectées dans le futur (logique non ? :p).
Ceci implique que toutes les VM du cluster doivent être arrêtées durant une longue période. C’est pourquoi il est très important de le vérifier pendant la phase de recette de la plateforme avant la migration de workload. Voici la procédure à suivre pour cette méthode :
rencontre homo à compiègne EDIT : Sur les dernières versions de nutanix, il faudra taper la commande ntp via le systemctl -> sudo systemctl start/stop/status ntpd.service
- Connectez-vous sur la première CVM du cluster en SSH et entrez la commande suivante : cluster stop (validez avec Y)
- Tapez : allssh date (pour vérifier une dernière fois :D)
- Arrêtez le démon ntp sur la CVM : sudo /etc/init.d/ntpd stop ***EDIT : sudo service ntpd stop /// sudo systemctl stop ntpd.service***
- Changez l’heure de la CVM manuellement : sudo ntpdate <IP NTP server>
- Démarrer le démon ntp sur la CVM : sudo /etc/init.d/ntpd start ***EDIT : sudo service ntpd start /// sudo systemctl start ntpd.service***
- Répétez l’opération sur chaque CVM du cluster
Une fois que vous avez attendu le temps nécessaire, vous pouvez redémarrer le cluster Nutanix grâce à la commande : cluster start. Si vous rejouez la commande du point précédent pour connaître l’offset, vous allez voir que celui-ci est revenu au alentour de 0 (allssh grep offset ~/data/logs/genesis.out). Attention, l’offset n’est disponible que sur le NTP leader, seul ce leader vous répondra à la commande.
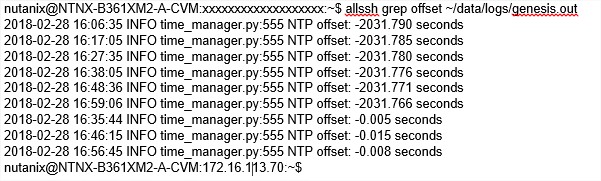
Offset de la CVM NTP leader
Vérifiez que vos serveurs NTP sont maintenant bien présents dans la commande : allssh ntpq -p

Configuration correcte
Extras
Si jamais vous avez toujours une erreur dans le NCC comme ceci : The NTP servers configured on the hypervisor ([‘xxx.xxx.xxx.xxx’]) differ from those configured in zeus config… Assurez-vous d’avoir les mêmes serveurs NTP dans Prism et ceux spécifiez dans la partie configuration des ESXi.
La KB Nutanix (ici) permet de vous aidez avec quelques exemples.
Comme d’habitude, si jamais vous avez le moindre problème : trouver un pseudo pour site de rencontre Support Nutanix :). Je vous conseille réellement de fixer ce problème parce que c’est important de faciliter le debug lorsqu’un problème fait surface dans votre infrastructure. Le temps de vos IPMI / ESXi / CVM doit impérativement être identique.